 Stories in Structure
Stories in Structure 
Scene of the Reconstruction
Have you watched the Bellingcat film? In case you haven’t, it follows a group of investigative journalists who uncover what really happened during the 2017 Atarib bombing in Syria. As tragic as the event was, their work is truly astonishing. They managed to create a time-aware 3D reconstruction of the street from videos and photos recorded by local people during the attack.
That was mind-blowing. Don’t we need 3D scanners or LiDAR to do that? Can we really just stitch together a handful of imperfect photos to recover the geometry of an object — or of a city?
To see what I mean, explore these 3D models of the recently destroyed Al-Shati and Jabalia districts in Gaza, also produced by Bellingcat.
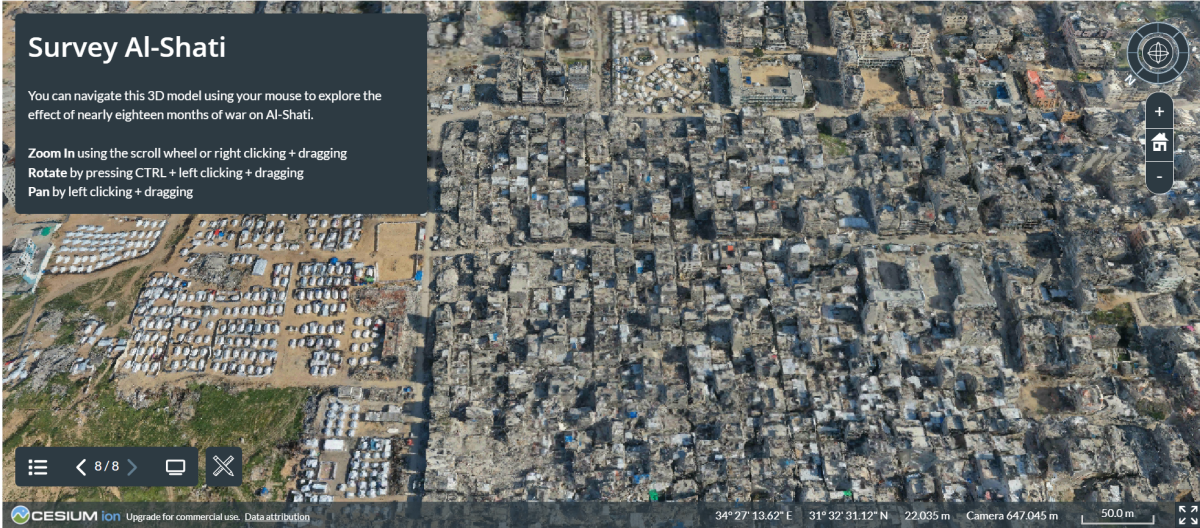
Figure 1: Screenshot of the Al-Shati 3D model from “Killing the Journalist Won’t Kill the Story” — Documenting the Destruction in Gaza From the Sky.
Mind you, I watched the Bellingcat film seven years ago. Technology has evolved: AI models have become remarkably good at guessing plausible 3D forms from just a few shots, especially for familiar object classes. But they still struggle to reconstruct arbitrary objects or large scenes faithfully.
Today, I’d like to invite you to join me in an investigation — to see whether we can preserve one valuable thing in its three-dimensional form, and whether there’s something curious about the structure we uncover.
In other words, let’s see how far curiosity and a few photographs can take us.
Investigator’s Toolbox
How do you rebuild a shape when all you have are photos? Think of this as the first step in any investigation: draw what you know, and see what’s missing.
Sketching the Truth
Let’s have a look at a photo of The Waiting sculpture to guide our thinking.

Figure 2: The Waiting sculpture in Wrocław, Poland.
From a single viewpoint, the sculpture is flat. Since we already have an idea of what people and armchairs look like, we can make an informed guess about its geometry — and this is exactly what AI models do: they make an informed guess based on the chairs and humans they were trained on.
To improve our certainty that the sculpture’s structure is as we imagine it, we would need more photos. Ideally, we would put our camera into motion and take photos from various angles and levels.

Figure 3: The Waiting from various viewpoints.
Even if you’ve never seen this sculpture in the real world, you can form a pretty good idea of how it looks by analyzing this handful of photos.
We can even follow features — or simply characteristic points — of the sculpture as they move through the photos. For instance, look at the right elbow (yellow dot) and the left knee (red dot) of the woman, and observe how their visibility, locations, and distance change as the camera moves.
These are just two sample points; nothing prevents us from choosing more: the ear, the nose, a finger, a specific hair “bubble,” the arms of the armchair, bumps on the back of the armchair, and so on. For each pair of features, we can again investigate their visibility, location, and distance for each camera position.
That gives us a lot of constraints — a lot of equations. And then it’s like solving a Sudoku puzzle: the solution tells us that the knee has to be exactly here and the elbow exactly there — otherwise, the constraints wouldn’t be satisfied and the whole puzzle would be wrong.
Once we solve the puzzle, we obtain a point cloud of features extracted from the photos. As if we were Claude Monet, sketching the sculpture in impressionist dots.
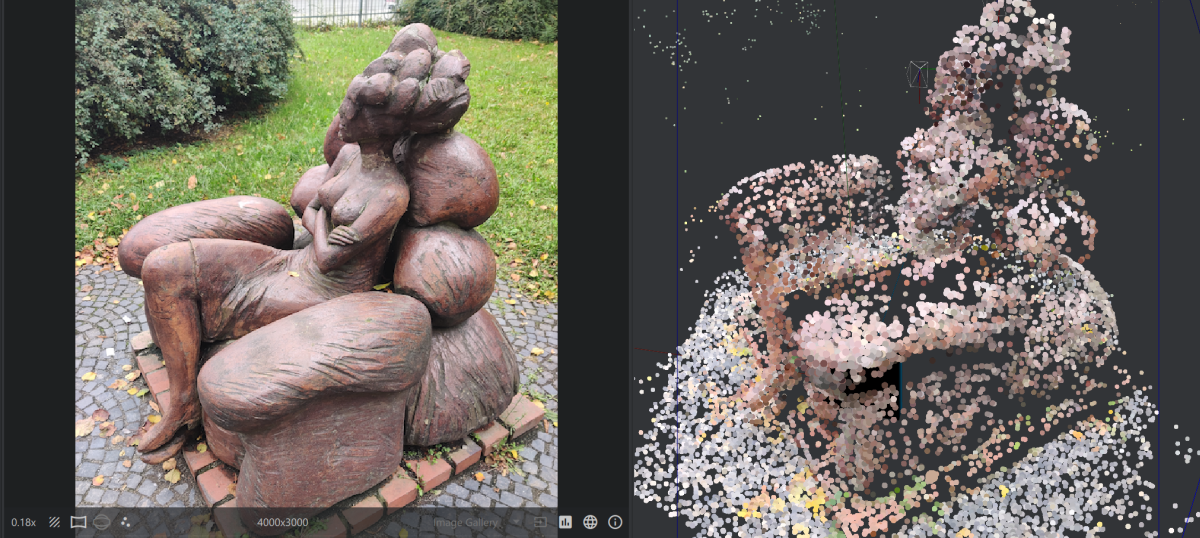
Figure 4: The Waiting sparse point cloud.
So far, we’ve drafted the truth and established the key facts. What comes next is the core of an investigator’s job — we need to connect the dots.
Refinement
A sparse point cloud is truth reduced to coordinates — a graph without edges. Enough to prove existence, not enough to reveal form.
The next step is simple: connect the nodes.
At this stage, the process is straightforwards. We look at known facts — our features, our characteristic points — and they serve as anchors (undeniable truth). Between those anchors lie pixels, and we can estimate where in space those pixels fall between the anchors. That’s how we densify the point cloud.

Figure 5: The Waiting dense point cloud.
Every 3D point also shares a spatial relation with points beside it — they are spatial neighbors. In our graph, that relation is represented by an edge. Curiously, we are not interested in pairs of neighbors, but in trios. We aim to discover small communities of three mutual neighbors and connect them in a triangle.
 Figure 6: Closer look at the knee of the The Waiting sculpture mesh.
Figure 6: Closer look at the knee of the The Waiting sculpture mesh.
From the standpoint of graph theory — this triangle is a small, three-node cycle. So the refined picture of truth is a graph filled with cycles, each cycle formed by three nodes, and every node belongs to at least one such cycle.
From the standpoint of computer graphics — this triangle is a mesh face. So the refined picture of truth is a mesh that can be rendered, 3D-printed, and stored on a hard drive.

Figure 7: The Waiting as a textured mesh.
Summary
We’ve followed the path of an investigation.
Starting with fragments — photographs, viewpoints, features — we reconstructed structure.
At its core was Structure-from-Motion: the algorithm that relates features and cameras, solving the optimization puzzle that reveals both a 3D point cloud and the positions and orientations of the cameras.
Around it, a sequence of other techniques helped refine the result: feature extraction, feature matching, Multi-View Stereo for densification, surface reconstruction for meshing, and texture mapping for color.
Together, they turned a set of flat images into a geometry of truth — a structure that lets us hold a fragment of reality in digital form.
That same logic is used by investigative journalists to recover what war or disaster tried to erase. But anyone can use it — to preserve a place, an object, or simply to see the hidden geometry of the world.
And as every investigation ends, a few new questions arise:
- What happens when we hand this process to AI?
- How do we scale it up, and how do we reference our geometry to the real world?
- What would it mean to look not just at what is there, but at what we notice?
Because in the end, every reconstruction begins with attention — where we choose to look, and what we decide to connect.
Before we turn to perception, in my next post we’ll take a brief detour into practice — a DIY reconstruction you can try yourself.
And after that, we’ll pay our attention to visual attention itself.