 Stories in Structure
Stories in Structure 
“What are you talking about?”
That’s essentially what our knowledge graph says when you hand it a question.
Naturally, you might try to ask it something. After all, it is a knowledge graph — it should be able to find relevant knowledge and produce an answer.
Yet, it doesn’t understand.
Which is a bit embarrassing, because we built the graph from text — specifically, my 2025 blog posts. But while the graph remembers entities and relationships between them, it doesn’t naturally know what to do with a fresh sentence dropped in front of it.
On one side we have a graph, like this conceptual graph below with red nodes depicting posts, green nodes depicting introduced concepts, and blue nodes marking abstractions.
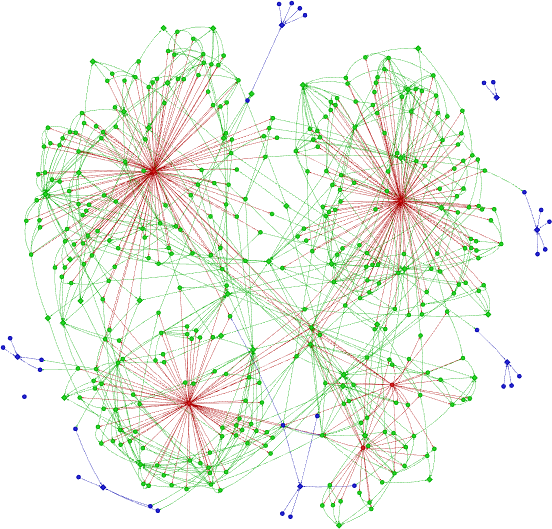
Figure 1. Conceptual graph of my 2025 blog posts.
On the other — a question. For example: What problem does Euler’s theorem solve, and what constraint makes it solvable?
These two don’t align, because they “speak different languages”.
And that leaves us with a problem: how do we translate a question into something the graph can actually understand?
First attempt: Just extract entities
If you recall the graph generation process, entities were extracted from fragments of my blog posts by an LLM given the ontology — the description of entity types and relationships. That worked. We got a graph, with some deduplication cleanup, but the core process was just: LLM + ontology + a simple prompt.
Let’s apply the same process to this question: “What problem does Euler’s theorem solve, and what constraint makes it solvable?”
Three entities are found:
- Euler’s Theorem (Concept)
- Problem Solved By Euler’s Theorem (Abstraction)
- Constraint That Makes It Solvable (Abstraction)
These look like entry points to the graph. Except they aren’t — at least not the last two.
The reason is simple: these entities don’t have to exist in our knowledge graph. So we managed to translate the question into entities, but the graph says “I know nothing about that, sorry!”.
Ensuring common vocabulary
What we are trying to solve here is known as entity linking — mapping a natural language query to entities that actually exist in the graph.
Clearly, using the same language is not enough. If you wanted to borrow a “rubber” and I only had an “eraser”, we wouldn’t communicate very well even though we would be talking about the same thing.
The problem is not understanding the question — it’s aligning it with the graph’s vocabulary.
That leads to a natural extension of the prompt: tell the LLM what entities are in the graph. That way we can ensure a common vocabulary.
I set the prompt to: “Given the following user question and a list of knowledge graph nodes, identify which nodes are relevant to answering the question.”
Question: “What problem does Euler’s theorem solve, and what constraint makes it solvable?”
Found Entities:
- Euler’s Theorem (Concept)
- Eulerian Path (Concept)
- Traversal (Concept)
- Single Stroke (Concept)
- Graph (Concept)
- Vertex (Concept)
- Edge (Concept)
- Undirected Graph (Concept)
- Node Degree (Concept)
- Odd Degree (Concept)
- Even Degree (Concept)
- abstract:Graph-Theoretic Properties and Degrees (Concept)
- abstract:Graph and Network Structures (Abstraction)
At this point we can have reasonable faith that these entities actually exist in the graph — the LLM is selecting from a known list rather than inventing names.
But wait. Where did “Node Degree” come from?
The LLM didn’t translate the question. It skipped ahead and started answering it.
“Node Degree” isn’t mentioned in the question — it’s the kind of thing you’d need to know to answer the question. The LLM, trying to be helpful, jumped straight to reasoning about the solution rather than mapping what was asked.
On one hand, that likely produces a useful answer. On the other, it bypasses the knowledge graph entirely — which rather defeats the purpose. So what if we actually want only the entities that follow directly from the question?
Being strict on requirements
You have to give an LLM strict boundaries, or it will try to be helpful and read your mind.
So the new prompt becomes explicit:
“Given the following user question and a list of knowledge graph nodes, identify only the nodes that are explicitly or very directly named by the question itself*. Do NOT include nodes that might be useful context or related background — only nodes whose concept is clearly present in the question.”*
Result:
Question: “What problem does Euler’s theorem solve, and what constraint makes it solvable?”
Found Entities:
- Euler’s Theorem (Concept)
One entity. From a question with two distinct sub-questions.
There’s a real gap between “what one says” and “what one means,” and this prompt falls entirely on the literal side. Allowing some mind reading feels beneficial — but how much before the LLM goes overboard and answers the question for us?
That’s a hard line to draw. Which suggests maybe entity linking isn’t the right frame at all.
Fundamentally different philosophy
Instead of asking “what entities are mentioned in the question?”, we ask “what entities feel similar to this question?”.
Following the GraphRAG community and, specifically, LangChain’s implementation of local search in GraphRAG, here’s the idea:
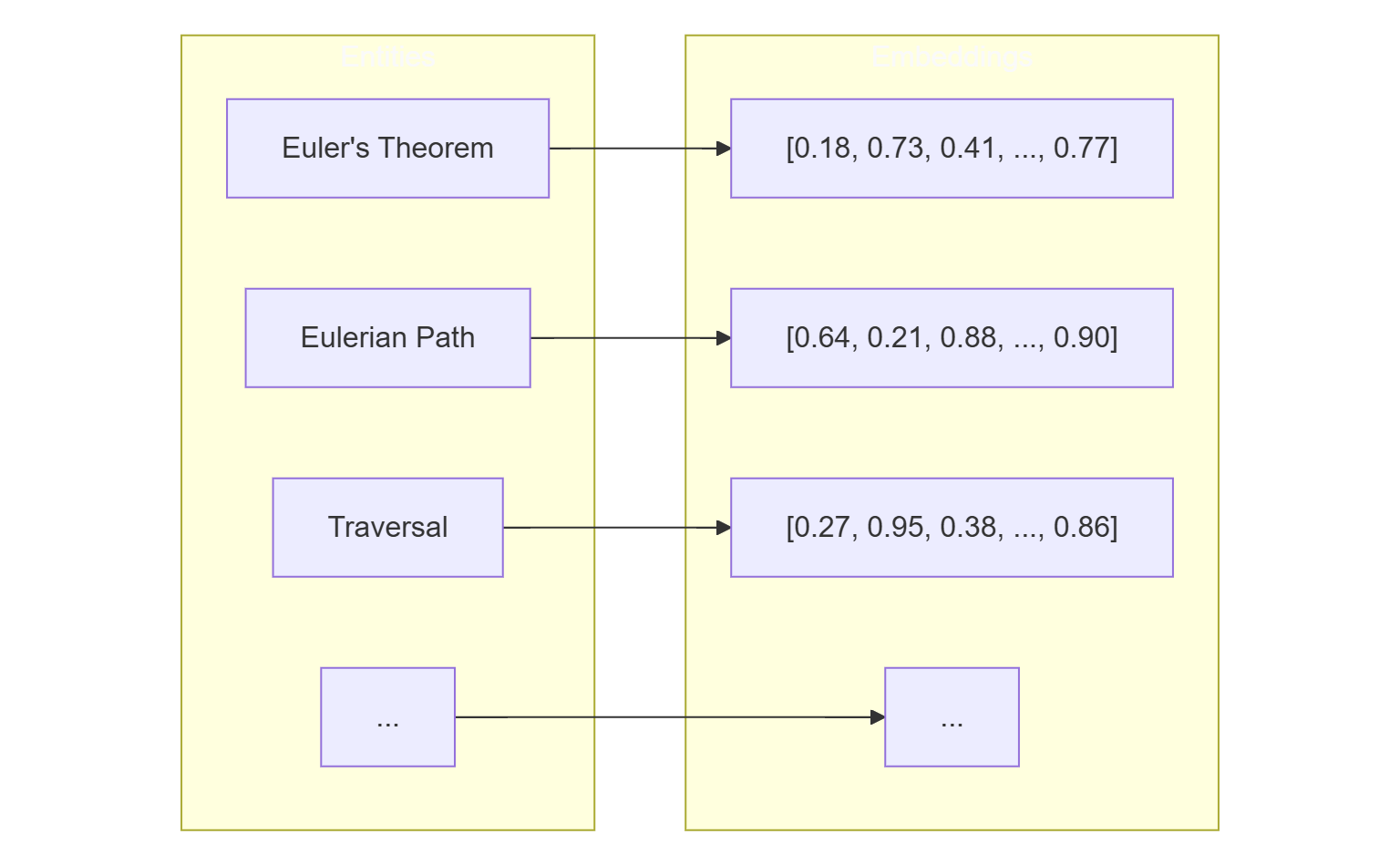
-
Encode all graph entities into embeddings (numeric vectors that capture meaning).
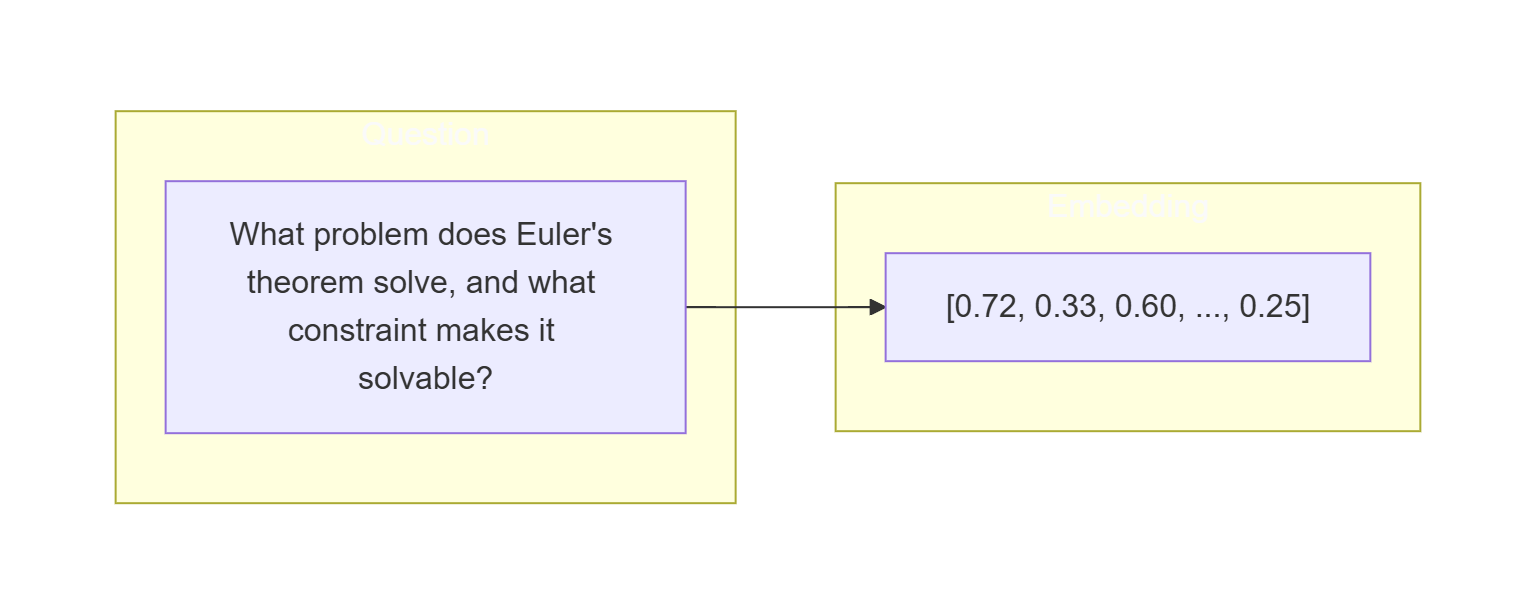
-
Embed a question
-
Calculate distance in meaning (i.e., semantic distance) between entities embeddings and the question embedding.
-
Use top k closest (e.g. k=5) as entry points to the knowledge graph.
This approach, called semantic retrieval, looks at graph entities and calculates which ones of them are the closest in meaning.
So what are those closest entities to our question?
Question: “What problem does Euler’s theorem solve, and what constraint makes it solvable?”
Top 5 Entities with similarity scores:
- Euler’s Question (Concept) - 0.599
- Euler’s Recipe (Concept) - 0.583
- Euler’s Theorem (Concept) - 0.580
- Leonhard Euler (Concept) - 0.544
- Euler 1735 Result (Abstraction) - 0.531
We now have two fundamentally different ways to enter the graph:
- map the question to known entities (entity linking)
- or map it to similar meaning (semantic retrieval)
They both produce entry points into the graph, but they get there differently. Entity linking tries to understand the question literally — and will either be too strict or too eager. Semantic retrieval doesn’t try to understand the question at all; it just asks “what in the graph feels like this?”
Semantic retrieval also has a practical advantage: it returns exactly k results, no more, no less. Entity linking gives you however many the LLM decides to return.
These differences matter — but which approach actually leads to better answers? That’s a harder question.
Wrapping up
The graph and the sentence speak different languages. To bridge them, I looked at two approaches: entity linking (map the question to named nodes) and semantic retrieval (find the nodes most similar in meaning).
Entity linking is precise but fragile — too literal and you get one node, too loose and the LLM answers the question for you. Semantic retrieval sidesteps that tension entirely by measuring meaning rather than matching names.
Both give us a way in. Which one leads somewhere more useful is what we’ll find out next.